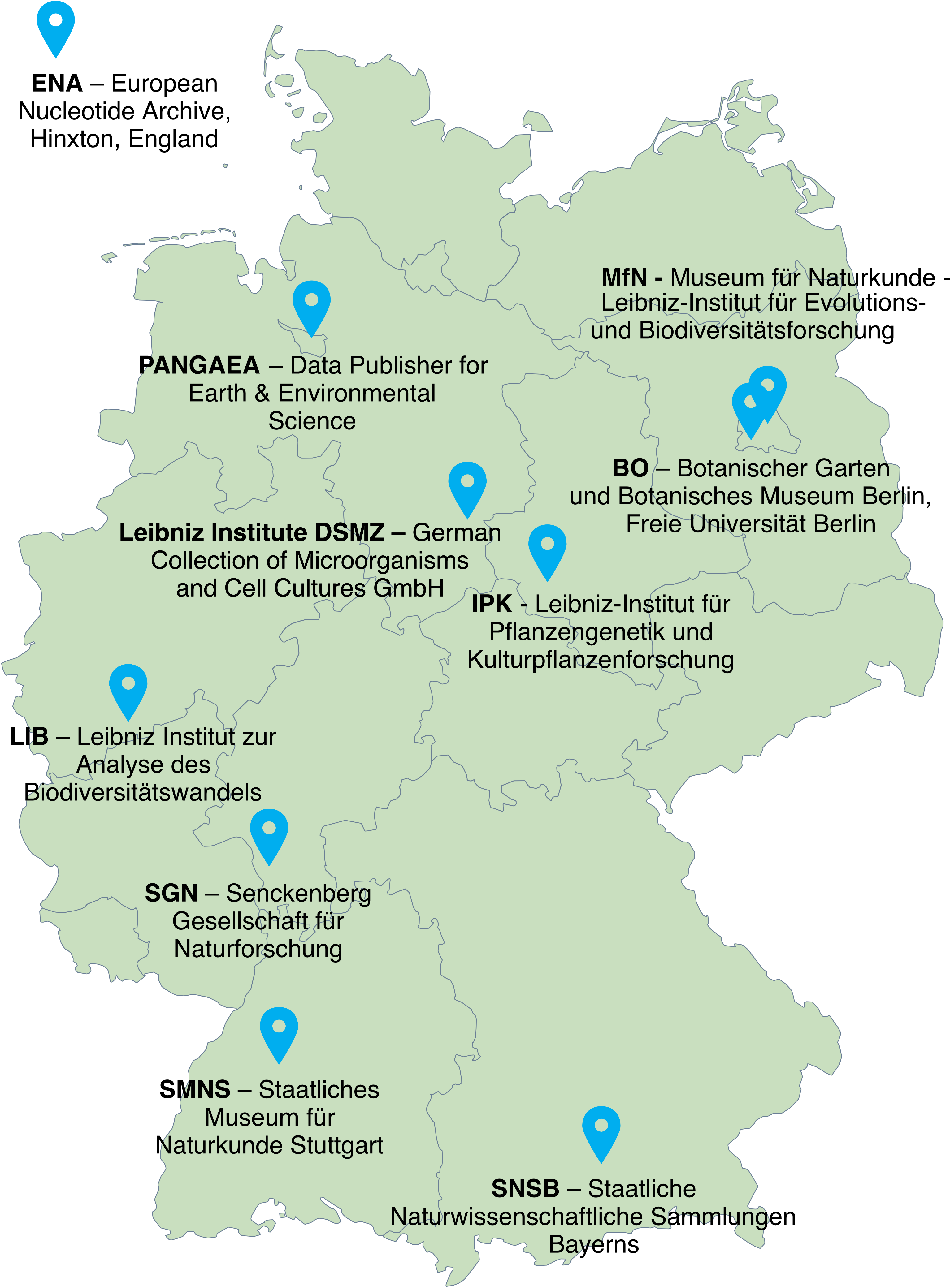
About the Data Center NetworkThe ten Data Centers listed below are are infrastructure partners in the GFBio broker network. They entail seven Data Centers located at natural history collections located throughout Germany . They are are and three Data Centers specialised in plant, nucleotide and environmental data. The Data Centers are departments of science informatics and data infrastructures at recognized recognised science institutions devoted to manage, store, archive and publish various types of bio- and geodiversity data. Data submitted through GFBio are transmitted to and curated by data curators at a matching GFBio Data Center, based on the profiles below. Data are available via various facets of the GFBio search portal, as well as on several other portals dependent on the Data Centers' scope, such as GBIF. The core group of ten GFBio data centers has agreed on a number of consensus documents, tools, data pipelines and standards and technical formats for interoperability. Data Submissions to the Data CentersData curationSubmitted data will be checked for quality and scope. If suitable for
| Panel |
|---|
| borderColor | black |
|---|
| bgColor | white |
|---|
|
| Section |
|---|
| Column |
|---|
Wondering if your data is suitable for archival & publication in one of the data centers |
|
|
, the curators are starting to harmonise the data set. This entails checking for mandatory fields, converting values in standardised formats (such as date, time or coordinates) and using standardised vocabulary (metadata standards) to describe the data. The curation process takes effort and the curator relies on the continuous communication with the data submitter. After the data undergo curation, the data Findability and Reusability are greatly enhanced and the data are ready to be archived and subsequently published. Data can be placed under moratorium to be published at a later date, however, the extension of the moratorium period is limited and varies according to the data centers policy.Shared archivalBiodiversity is influenced by many factors. Therefore, data generated to answer questions about biodiversity are often heterogeneous and looking at different aspects of biodiversity, such as the occurrence of species in a certain environment. To be able to archive the data in the most suitable repository, the heterogenous data sets are divided, archived in the respective data centers and interlinked via their persistent identifiers. | Create from template |
|---|
| templateName | 117899265 |
|---|
| templateId | 117899265 |
|---|
| buttonLabel | Data center page |
|---|
|
| Column |
|---|
 Image Added Image Added
|
|
|
|