Status: PRODUCTIVE
Overview
![]()
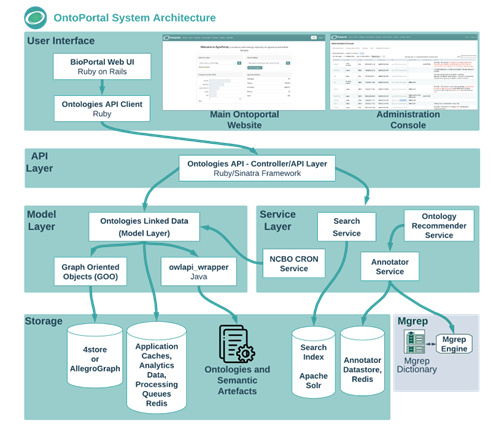
BiodivPortal is a dedicated instance of the OntoPortal technology for biodiversity related terminologies. OntoPortal is a generic technology to build terminology repositories and catalogues. The OntoPortal system architecture is structured in several layers:
- The storage layer contains a triple-store which saves each terminology in a distinct graph, as well as other data (metadata records, mappings, users, etc.). This layer also uses: (i) Redis-based key-value storage for application caches and the Annotator dictionary datastore; (ii) Solr search engine to index terminology content for retrieval with the Search service.
- The model layer implements all the mechanisms to parse the terminology source files using the OWL-API and retrieve them from the triple-store using a built-in Object-Relational-Mapping library (GOO).
- The service layer implements the core OntoPortal services: Search, Annotator and Recommender.
- The API layer implements a unified API for all the models (e.g., Class, Instance, Ontology, Submission, Mapping, Review, Note, User) and services supported by OntoPortal. The API can return as default a JSON-LD format.
- The user interface offers a set of various views to display and use the services and components built in the API layer. The UI is customized for logged-in users and for groups/organizations that display their own subset of resources. Administrators of the OntoPortal instance have access to an additional administration console to monitor, and manage the content of the portal.